Dataset Management Command:dataset
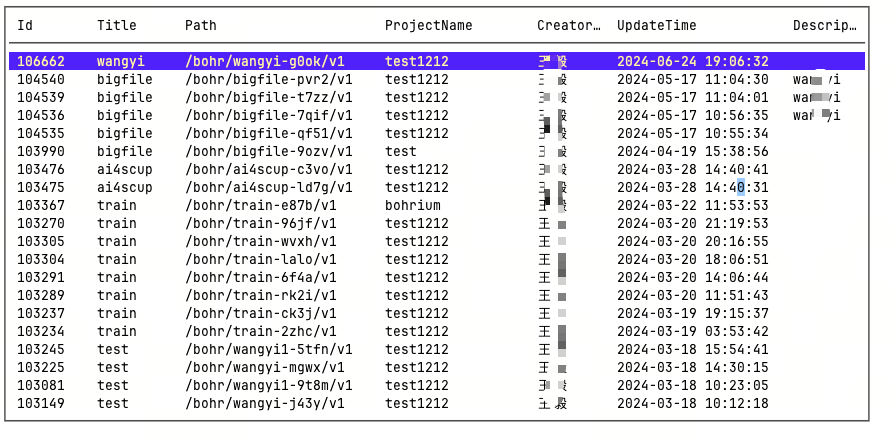
List all datasets:list
Command Entry:
bohr dataset list
Summary:
Usage:
bohr dataset list [flags]
Aliases:
list, ls
Flags:
--csv output with CSV format
-h, --help help for list
--json output with JSON format
--noheader does not print header information
-n, --number int number of results to be displayed (default 50)
-p, --projectId int Specify project ID to filter results
-t, --title string Search title
--yaml output in YAML format
Parameter description:
| Parameter | Abbreviation | Description | Required |
|---|---|---|---|
| --number | -n | Display a certain number of datasets.(default 50) | No |
| --projectId | -p | Display the datasets under the project ID. | No |
| --title | -t | Search for dataset name. | No |
Example:
bohr dataset list -t bigfile --yaml
# View the latest 50 datasets with the title "bigfile" in YAML format
bohr dataset list -p 123 -n 10
# View the first 10 datasets with project ID 123.
Delete datasets:delete
Command Entry:
bohr dataset delete
Summary:
Usage:
bohr dataset delete <datasetId>... [flags]
Flags:
--datasetId ints DatasetId(s) (can be used multiple times)
-h, --help help for delete
Parameter description:
| Parameter | Abbreviation | Description | Required |
|---|---|---|---|
| --datasetId | - | Dataset Id | yes |
Example:
bohr dataset delete 123 234
# Delete the datasets with IDs 123 and 234.
Create dataset:create
Command Entry:
bohr dataset create
Summary:
Usage:
bohr dataset create [flags]
Examples:
$ bohr dataset create
Flags:
-m, --comment string dataset description
-h, --help help for create
-l, --lp string file local path
-n, --name string dataset name
-p, --path string dataset path
-i, --pid int project id
Parameter description:
| Parameter | Abbreviation | Description | Required |
|---|---|---|---|
| --comment | -m | Dataset Description | 否 |
| --name | -n | Dataset Name | 是 |
| --path | -p | Dataset Path | 是 |
| --pid | -i | project ID | 是 |
| --lp | -l | project id | 是 |
Example:
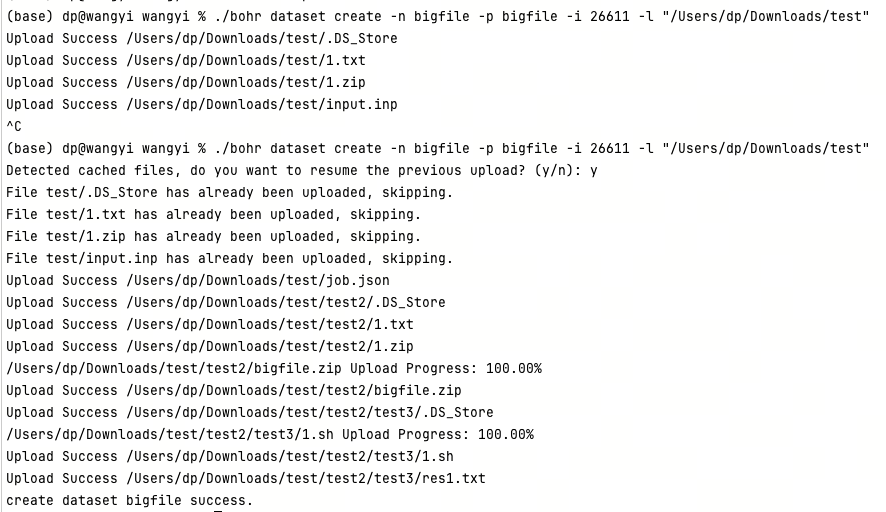
bohr dataset create -n bigfile -p bigfile -i 26611 -l "/Users/dp/Downloads/test"
# Upload the "test" folder to the "bigfile" dataset
# If interrupted during upload, re-run the command and enter 'y' to resume